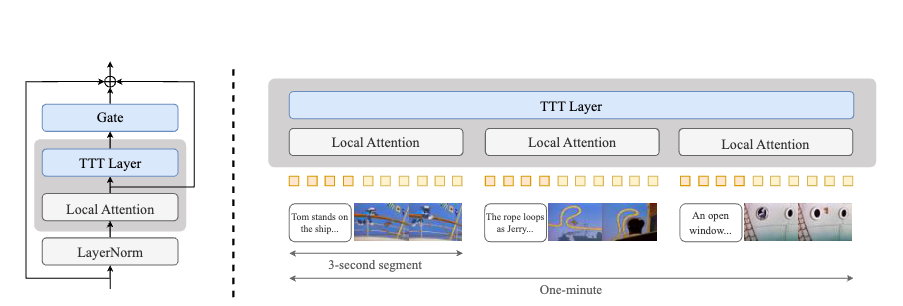
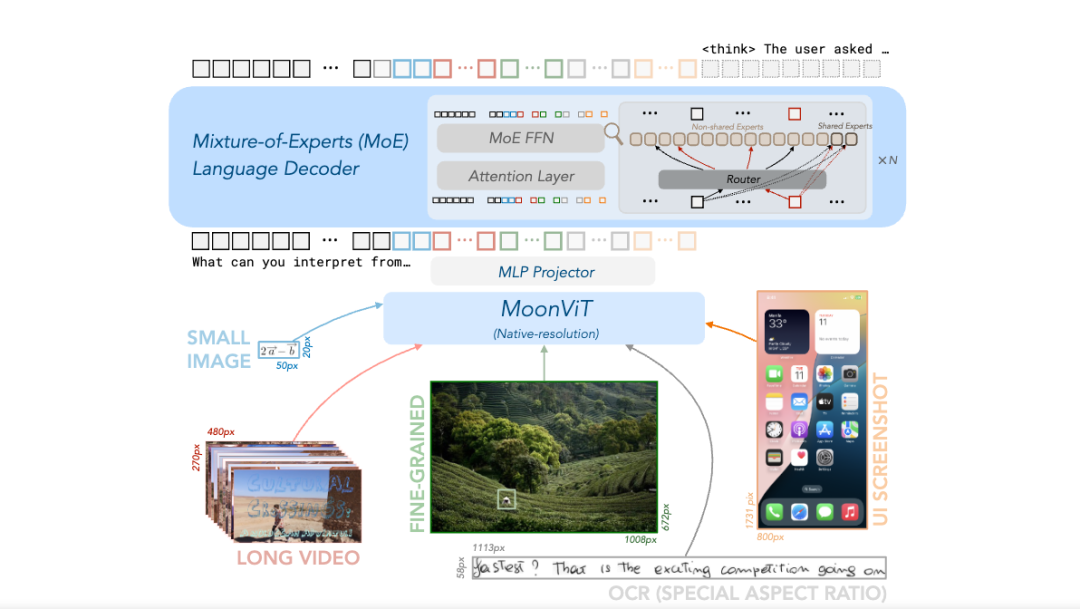
场景一致性、运动自然性都有惊人的表现。如追逐的场景,各个物体的属性、颜色、形状,以及和空间布局一致性都没有崩坏,证明了模型长期记忆的能力。想象一下动画片里汤姆追逐杰瑞的经典场面:汤姆可不是简单地直线跑,他会急刹车、猛转弯、跳起来躲避障碍,甚至被砸扁后像弹簧一样恢复。这些看似夸张混乱的动作,其实也包含物理逻辑。但要让 AI 理解这种复杂的动态场景并不容易。过去 AI 模型(比如用到MLP技术的)需要学会描绘这种「不走直线」的运动轨迹。现在 AI 有了一支灵活的「画笔」(MLP的隐藏状态),让它能捕捉汤姆突然加速、变向、摔倒滚成球等各种非线性的、但又符合物理规律的运动变化,而不是只能画直线。前面提到的 TTT 层,核心创新就像给汤姆加了一个「外挂」,让他拥有超强的「临场反应」能力,能根据实时路况(新数据)微调自己的动作。比如汤姆能看到香蕉皮的那个瞬间(测试时),立刻调整自己的脚步和姿势(动态调整神经网络参数),试图躲开或者以一种夸张的方式滑倒(上下文自适应)。他不再靠以前摔倒的经验(静态训练好的模型),而是当场学习和反应(测试时自监督学习)不过,基础模型,本身对复杂动作的学习不够完美,即使加了 TTT 层,有些错误还是会出现。对于模型能力而言,如何提高视觉处理能力,始终是一个「长期主义」任务。Kimi 新开源的 Kimi-VL,就是在模型的视觉能力上继续钻研提高。在这次开源的论文中可以看到,Kimi 用原生高分辨率视觉编码器 MoonViT,来突破传统视觉编码的限制。传统方法(如 LLaVA-OneVision)需将高分辨率图像分割为子图再拼接,导致信息丢失和计算冗余。MoonViT 基于 NaViT 的打包策略,将不同分辨率的图像拆分为块并展平为序列,结合 2D 旋转位置编码(RoPE),直接处理原生分辨率图像,保留细粒度视觉信息。用人话来说,汤姆过去想抓住杰瑞,只能通过好几个小窗户去看一个大房间(LLaVA-OneVision)。MoonViT就像给汤姆换上了一副超高清、广角、还能自动变焦的「超级眼镜」。他可以直接看到整个房间(处理原生高分辨率图像),无论是墙上的小洞还是桌上的面包屑都一清二楚(保留细粒度信息),而且看得又快又好。同时,Kimi 首次将 MoE 深度整合到视觉语言模型,跨模态的专家协作,能让语言模型在保留纯文本能力(如代码生成)的同时,激活视觉专家处理图像、视频等多模态输入。对于视觉-语言的多模态任务而言,模型架构层的研究至关重要,因为多模态数据的异质性、交互复杂性以及任务多样性对模型的表示能力、计算效率和泛化性提出了独特挑战。想让 AI 能看、能听、能跑、能思考,它的内部模型架构就至关重要。你不能简单地把眼睛(视觉模块)和耳朵(音频模块)、大脑(语言处理)零件堆在一起。必须精心设计它们如何连接、如何协同工作(融合异构数据、跨模态关联),才能让 AI 流畅地根据看到的画面和听到的声音做出反应,甚至理解一个包含画面和对话的故事。更复杂的是,当我们要让 AI 生成长视频时,它不仅要保证画面好看,还得让整个故事情节前后连贯,讲一个完整的故事而不是随意堆砌场景,一分钟的 AI版《猫和老鼠》还是一个雏形。未来,随着 3D 视觉、音频等多模态扩展,架构研究需进一步探索,跨模态动态路由,结合 TTT 思想设计跨模态交互层,或进一步优化隐藏状态的表达能力(如引入 Transformer 作为隐藏网络),或许是多模态模型架构研究的重要方向。当大模型拥有了这全套「感官」,那些能帮我们干活但稍显愚蠢的通用 AI Agent ,可用性也将大大提升。